In this post we create a database schema for our blog with DBIx::Class and scrape the surface of its capabilities.
Mojolicious Series
- Part 01 - Introduction
- Part 02 - Routing and Rendering
- Part 03 - Forms, Logins
- Part 04 - Database schemas with DBIx::Class
- Part 05 - DBIx::Class Integration in Mojolicious
- Part 06 - Schema Versioning with DBIx::Class::Migration
- Part 07 - Relationships with DBIx::Class
DBIx::Class (DBIC) is a flexible Object Relational Mapper for abstracting SQL tables and queries within Perl. It allows us to specify SQL tables as classes and thus avoid writing SQL manually in our app. Yet for understanding this post, I assume you have at least some basic understanding of SQL.
Update 10/2014: sri wrote an awesome asynchronous wrapper around DBD::Pg called Mojo::Pg that works great alongside Mojolicious. If you're planning on using PostgreSQL and do not require the functionality that comes with a large ORM as DBIC (and also avoid their signficant overhead), you should check it out – It even has migration support :)
Nonetheless, I wrote the tutorial for DBIC, and despite the overhead, it provides quite some enjoyable convenience for larger applications, especially If you want to access the database schema in other modules.
Basic Concepts
Let's start with the basic terminology. As with SQL, DBIC needs some kind of table structure that defines the available columns within that table. In DBIC, the equivalent of a SQL table is the Result class: It is the single location where you define your data columns and relationships to other tables.
Assume you have a set of result classes defined, and you want to modify
them. If you would work with the database directly, you would use SQL
queries to search (e.g., SELECT * FROM), delete (DELETE FROM), etc.
In DBIC, anytime you want to modify data in that fashion, you create a ResultSet on the result class you want to work with.
Creating the Database Schema
We first define the schema we will be using within our app. We want to create and modify/delete blog posts. For this task, the basic model is very simple, as that is basic CRUD within a single table.
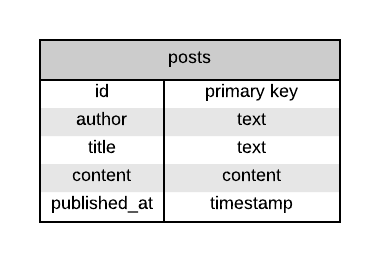
For the organization of our database schema, we have two options:
- Embed the schema within our Mojolicious application. Use this if the schema will only be used within your application
- A separated schema perl module. This can be distributed and installed independently. Use this, if you might want to access your database in other projects.
For the blog app in this series, we won't be needing a separated module. But when building your own schema, think about those two options. If there is the slightest possibility to use the schema in another project, use the second option without hesitation. The organization of two modules may be a tad more complex, but it will pay off in the long run.
For variant one, we add the following files to our application:
1
2
3
4
5
6
7
8
moblo
├── lib
│ ├── Moblo
│ │ ├── Schema
│ │ │ └── Result
│ │ │ └── Post.pm
│ │ └── Schema.pm
├─ ...
This adds two new modules to the app. Moblo::Schema is
the main schema module, through which our schema can be imported later
on. The module definition is really trivial, and we won't need to change
it anytime soon:
1
2
3
4
5
6
7
8
package Moblo::Schema;
# based on the DBIx::Class Schema base class
use base qw/DBIx::Class::Schema/;
# This will load any classes within
# Moblo::Schema::Result and Moblo::Schema::ResultSet (if any)
__PACKAGE__->load_namespaces();
The other module is Moblo::Schema::Result::Post, the
result class we define our posts table in.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
package Moblo::Schema::Result::Post;
use base qw/DBIx::Class::Core/;
# Associated table in database
__PACKAGE__->table('posts');
# Column definition
__PACKAGE__->add_columns(
id => {
data_type => 'integer',
is_auto_increment => 1,
},
author => {
data_type => 'text',
},
title => {
data_type => 'text',
},
content => {
data_type => 'text',
},
date_published => {
data_type => 'datetime',
},
);
# Tell DBIC that 'id' is the primary key
__PACKAGE__->set_primary_key('id');
For our current feature set, this definition is all we need.
Creating the Database
With the schema definition completed, we need a way to generate SQL definitions to create the actual database. The following script is a minimal example to deploy the tables to a SQLite database. Note that in this example, the database is created in the current working directory of the script.
1
2
3
4
5
6
7
use strict;
use warnings;
use Moblo::Schema;
my $schema = Moblo::Schema->connect('dbi:SQLite:moblo.db');
$schema->deploy();
Important: Keep in mind that if you later update your schema, you will have to think about upgrade paths in your database.
A more sophisticated, but also complicated option, is using a versioning toolkit that supports migrations. We employed DBIx::Class::Migration for this task. It is a powerful migration engine with support for multiple databases that reduces the pain of database versioning to an acceptable level. We will move Moblo::Schema over to migrations in one of the next posts. For now, let's concentrate on DBIx::Class itself and for the time being, using the generated SQLite DB is fine.
Side note: Creating a schema from existing database
With DBIC, it is also possible to dump an existing database from an
existing database. One way to dump the schema classes is dbicdump,
which is contained in the
DBIx::Class::Schema::Loader
distribution.
1
$ dbicdump -o dump_directory=lib/ Moblo::Schema dbi:SQLite:moblo.db
Connecting to the schema
The SQLite database has been created with the contents of our
schema. Before performing queries on a connected schema, we have to
create a schema instance. Now the schema main module Moblo::Schema
comes into play. You can use its inherited connect method
to initiate a schema instance using a DBI data source
string.
1
2
3
4
# DSN syntax
# dbi:DriverName:database=database_name;host=hostname;port=port
# For SQLite:
my $schema = Moblo::Schema->connect('dbi:SQLite:foo.db');
ResultSets – Actually using the Database
With the above schema instance available, actually using the database is now a breeze. You just create a ResultSet instance of your result class as follows and then CRUD away as much as you want!
1
my $rs = $schema->resultset('Post');
Note: The attribute to ->resultset is the result
class basename, not the table name and is case sensitive.
Adding a post to the database
1
2
3
4
5
6
INSERT INTO posts (author, title, content, date_published) VALUES('first', ...)
$rs->create({
author => 'Max First',
title => 'Some interesting story',
content => 'This really is interesting ... ',
});
Searching for posts
1
2
3
4
5
6
7
8
9
10
# SELECT * FROM posts WHERE author = 'Max First';
my $query_rs = $rs->search({ author => 'Max First' });
my $first = $query_rs->first;
print $first->title;
# Iterate all posts by this author
while (my $post = $rs->next) {
print $post->title;
}
Updating a post
1
2
3
4
my $first = $rs->first;
# UPDATE posts SET author = "Max Peter Jr." WHERE id = 1
$first->update({ firstname => 'Max Peter Jr.' });
Deleting posts
1
2
3
4
5
6
7
# SELECT * FROM posts WHERE id IN (1,2,3,..,10)
my $delete_rs = $rs->search({ id => { '-in' => [ 1 .. 10] } });
# How many are we going to delete
print $delete_rs->count;
$delete_rs->delete;
This should give you a glimpse of the basic manipulation functionality in DBIC. Of course, practical uses of a sophisticated ORM like DBIC will be much more complicated (think relationships, joins, advanced SQL-agnostic searching for the beginning) that we haven't looked into at all. There is much to learn, but DBIC provides means to achieve all your database needs.
In the next part, we integrate DBIx::Class schema into our Mojolicious app.
Additional Documentation
- DBIC has an extensive, pod-based manual: DBIx::Class::Manual
- The
searchmethod uses SQL::Abstract to construct the query.
Code at GitHub
You can browse the app at the current state as well as its history on Github.